7 Data Engineering Projects To Put On Your Resume

Starting new data engineering projects can be challenging. Data engineers can get stuck on finding the right data for their data engineering project or picking the right tools.
And many of my Youtube followers agree as they confirmed in a recent poll that starting a new data engineering project was difficult.
Here were the key challenges they called out.
- Identifying suitable data sets for the project.
- Selecting the appropriate tools to employ.
- Determining the subsequent steps once the data is acquired.
So to help inspire you I have collected several examples of data engineering projects that should help drive you forward.
What should you look for in a data engineering project?
Before starting I wanted to help provide a few tips.
When you look to build a data engineering project there are a few key areas you should focus on.
- Multiple Types Of Data Sources(APIs, Webpages, CSVs, JSON, etc)
- Data Ingestion And Orchestration Tools Like Azure Data Factory, SSIS,Mage and Airflow
- Data Storage – such as Snowflake, BigQuery, Apache Iceberg or Postgres
- Data Visualization (So you have something to show for your efforts).
- Use Of Multiple Tools (Even if some tools may not be the perfect solution, why not experiment with Kinesis or Spark to become familiar with them?)
Each of these areas will help you as a data engineer improve your skills and understand the data pipeline as a whole. In particular, creating some sort of end visual, especially if it involves creating a basic website to host it can be a fun way to show your projects off.
But enough talk, let’s dig into some ideas for your data engineering projects.
Predictit Data With Airflow And Snowflake
Pulling data from APIs and storing it for later analysis is a classic task for most data engineers. Whether it’s Netsuite or Lightspeed POS, you’ll likely need to create a data connector to pull said data.
So this first project has you pull data for your data engineering project from Predictit.
Here is the general outline.
- Data Source: The data source for this is PredictIt, a marketplace for political predictions.
- Ingestion Method: You’ll use a Python operator in Airflow and run it in Managed Workflows for Apache Airflow (MWAA) for ease of use.
- Data Storage: The raw data will be stored in an S3 bucket. From there, the data will be transferred to Snowflake for analytical storage.
- Data Transformations: There are a lot of ways you can transform data, but you can always use Snowflake’s tasks to perform data transformations.
- Visualization: Tableau will be used for data visualization purposes.
You’ll use these tools to create a basic function for scraping JSON data from a Predicted API endpoint. He explains the structure of the data and how it will be loaded into S3.
Then you will use Airflow to create a DAG (Directed Acyclic Graph) that defines the workflow for the project. The DAG includes tasks for scraping data and a dummy task called “ready,” which aids in referencing the last task of a DAG.
From there you can take said data to build a data visualization of what is going on in the political landscape. Who is currently taking the lead in terms of bettings lines?
But this is just a basic example of a data engineering project. Let’s dig into another great example of a data engineering project.

In this project, you will explore an Uber-like dataset. It was created by Darshil who makes, probably the best data engineer project videos on Youtube. This currently being the most popular.
By following the steps outlined in the video, you’ll learn how to build a data pipeline, model data and so much more.
The project involves the following steps:
- Data Source: Uber data set, provided in the Git repo.
- Ingestion Method: You’ll use Mage and Python to orchestrate and ingest the data
- Data Storage: The raw data will be stored in Google Cloud Storage and BigQuery
- Data Transformations: You’ll once again use Mage to run your transforms.
- Visualization: Google Looker Studio
Architecture Overview: Before diving into the project details, let’s gain an understanding of the architecture that forms the foundation of our data pipeline. We will leverage Google Cloud services to store, transform, and visualize the data. The architecture diagram consists of key components like Google Cloud storage, compute engine, BigQuery, and Looker. These services work seamlessly together to ensure efficient data handling and analysis.
Focus On Analytics With StackOverflow Data
What if you could analyze all or at least some of the public Github repos. What questions would you ask?
Felipe Hoffa has already done some work on this type of project where he analyzed terabytes of data over several articles from the Google BigQuery data collection.
But with so much data, there is a lot of opportunities to work on some form of analytical project. Felipe, for example, analyzed concepts like:
- Tabs vs Spaces?
- Which programming languages do developers commit to during the weekend?
- Analyzing GitHub Repos for comments and questions
There are so many different angles you could take on this project and it provides, you, the data engineer a lot of creativity in how you think about data.
You can analyze the source code of 2.8 million projects.
Maybe you can write an article like What StackOverflow Code Snippets Can We Find In GitHub?
In addition, this project idea should also point out that there are plenty of interesting data sets you can use out there that exist on platforms like GCP and AWS. So if you don’t feel like scraping data from an API, you can always work on your analytical chops on the hundreds of data sets these two cloud providers to offer.
Web scraping is always a great way to start your data engineering project. There is what feels like unlimited data you can access online and I have put together several examples of projects that use web scraping as their data source. Now you can code this or use solutions depending on how complex the problem is you’re trying to solve.
In the examples provided, you can scrape data from G2 or the Washington State Senate.
Here is the general outline.
- Data Source: Online sources including G2 and Washington Senate
- Ingestion Method: Python and BrightData
- Data Storage: Snowflake
- Data Transformations: SQL and Python
Scraping Inflation Data And Developing A Model With Data From CommonCrawl
Another interesting project was conducted by Dr. Usama Hussain, where he measured the rate of inflation by tracking the change of price of goods and services online. Considering that the BBC reports that the United States has seen the largest inflation rate since 2008, this is an important topic.
In this project, the author used petabytes of web page data contained in the Common Crawl.
I also think this is another great example of putting together and displaying a data engineering project. One of the challenges I often reference is how hard it can be to show off your data engineering work.
Here is the general outline.
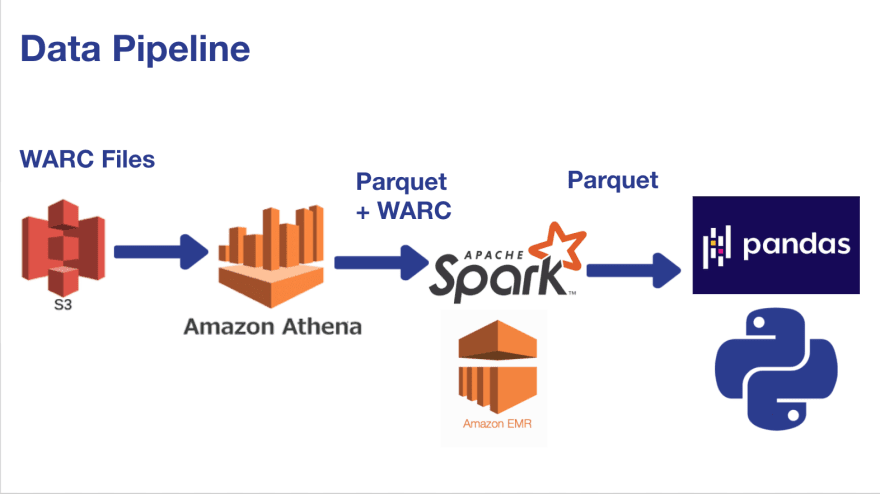
- Data Source: Inflation data
- Ingestion Method: Spark
- Data Storage: The raw data will be stored in an S3 bucket..
- Data Transformations: Pandas
But Dr. Hussain’s project is documented in a way that shows off what work was done and the skills that he has, without having to dig into all of the code.
Dr. Hussain outlines the data pipeline below.
Data Engineering Project for Beginners – Batch edition
This final data engineering project is brought to us by Start Data Engineering(SDE). While they seem to reference just a basic CSV file about movie reviews, a better option might be to go to the New York Times Developers Portal and use their API to pull live movie reviews. Use SDE’s framework and customize it for your own needs.
SDE has done a superior job of breaking this project down like a recipe. They tell you exactly what tools you need and when they are going to be required for your project. They list out the prerequisites you need:
In this example, SDE shows you how to set up Apache Airflow from scratch rather than using the presets. You will also be exposed to tools such as:
There are many components offered, so when you are out there catching the attention of potential future employers, this project will help you detail the in-demand skills employers are looking for.
Conclusion
If you are struggling to begin a project, hopefully, we’ve inspired you and given you the tools and direction in which to take that first step.
Don’t let hesitation or a lack of a clear premise keep you from starting. The first step is to commit to an idea, then execute it without delay, even if it is something as simple as a Twitter bot. That Twitter bot could be the inspiration for bigger and better ideas!
Thanks for reading! If you want to read more about data consulting, big data, and data science, then click below.
How to build a data pipeline using Delta Lake
A comprehensive introduction to change data capture (CDC)
Intro To Databricks – What Is Databricks
Is Apache Airflow Due for Replacement? The First Impression Of mage-ai
analytics Big Data data engineering Data Science Machine Learning